
Image Credit: http://continuousdelivery.com
The principles of Continuous Delivery
and DevOps have been around for a few years. Developers and system
administrators who follow the lean-startup movement are more than
familiar with both. However, more often than not, implementing either
or both within a traditional, large IT environment is a significant
challenge compared to a new age, Web 2.0 type organization (think
Flickr) or a Silicon Valley startup (think Instagram). This is a case
study of how the consultancy firm I work for delivered the largest
software upgrade in the history of one blue chip client, using both.
Background
The client, is one of Australia's
largest retailers. The firm I work for is a trusted consultant
working with them for over a decade. During this time (thankfully),
we have earned enough credibility to influence business decisions
heavily dependent on IT infrastructure.
A massive IT infrastructure upgrade was
imminent, when our client wanted to leverage their loyalty rewards
program to fight competition head-on. With an existing user base of
several millions and our client looking to double this number with
the new campaign, the expectations from the software was nothing
short of spectacular. In addition to ramping up the existing
software, a new set of software needed to be in place, capable of
handling hundreds of thousands of new user registrations per hour.
Maintenance downtime was not an option (is it ever?) once the system
went live (especially during the marketing campaign period).
Why DevOps?
Our long relationship with this client
and the way IT operations is organized meant that adopting DevOps was
evolutionary than revolutionary. The good folk at operations have a
healthy respect and trust towards our developers and the feeling is
mutual. Our consultants provided development and 24/7 support for the
software. The software include a Web Portal, back office systems,
partner integration systems and customer support systems.
Adopting DevOps principles meant;
- That our developers have more control over the environments the software runs in, from build to production.
- Developers have better understanding of the production environment the software eventually run in, opposed to their local machines.
- Developers are able to clearly explain to infrastructure operations group what the software does in each environment.
- Simple clear processes to manage the delivery of change.
- Better collaboration between developers and operations. No need to raise tickets.
Why Continuous Delivery?
The most important reason was the
reduced risk to our client's new campaign. With a massive marketing
campaign in full throttle, targeting millions of new user sign-ups,
the software systems needed to maintain 100% up-time. Taking software
offline for maintenance, meant lost opportunity and money for the
business.
In a nutshell;
- A big bang approach would have been fine for the initial release. But when issues are found we want to deliver fixes without down time.
- When the marketing campaign is running, based on analytics and metrics, improvements and features will need to be done to the software. Delivering them in large batches (taking months) doesn't deliver good business value.
- In a developer's perspective, delivering small changes frequently helps to identify what went wrong easily and either roll back or re-deploy a fix.
- Years of Agile practices followed by us at the client's site ensured that a proper culture is in place to adopt continuous delivery painlessly.
- We were already using Hudson/Jenkins for continuous integration.
- We only needed the 'last mile' of the deployment pipeline to be built, in order to upgrade the existing technical process to a one that delivered continuously.
The process: keep it simple and transparent
The development process we follow is simple and the culture is such, that each developer is aware that at any given moment one or more of their commits can be released to production. To make the burden minimum, we use subversion tags and branching so that release candidate revisions are tagged before a release candidate is promoted to the test environment (more on that later). The advantage of tagging early is that we have more control over changes we deliver into production. For instance, bug fixes versus feature releases.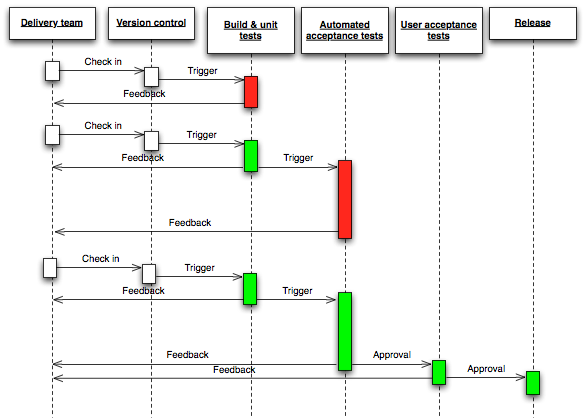
{kind=link}
The production environment consists of a cluster of twenty nodes. Each node contains a Tomcat instance fronted by Apache. The load balancer provides functionality to release nodes from the cluster when required, although not as advanced as API level communication provided by Amazon's elastic load balancer (this is an investment made by the client way back, so we opted to work with it than complaining).
Jenkins CI is used as the foundation
for our continuous delivery process. The deployment pipeline consists
of several stages. We kept the process simple just like the diagram
above, to minimize confusion.
- Build – At this stage the latest revision from Subversion is checked out by Jenkins at the build server, unit tests are run and once successful, the artifacts bundled. The build environment is also equipped with infrastructure to test deploy the software for verification. Every build is deployed to this test infrastructure by Jenkins.

Creating a
release candidate build with subversion tagging.

Promotion
tasks
- Test (UAT) – Once a build is verified by developers, it's promoted to the Test environment using a Jenkins task.
- A promotion indicates that the developers are confident of a build and it's ready for quality assurance.
- The automated promotion process creates a tag in Subversion using the revision information packaged into the artifacts.
- Automated integration tests written using Selenium is run against the Test deployment.
- The QA team uses this environment to carry out their testing.
- Production Verification – Once artifacts are tested by the test team and no failures reported by the automated integration tests, a node is picked from the production cluster and – using a Jenkins job – prepared for smoke testing. This automated process will;
- Remove the elected node from the cluster.
- Deploy the tested artifacts to this node.

Removing a
node from the production cluster.

Nominating
a node (s) for production verification.
- Production (Cut-over) – Once the smoke tests are done, the artifacts are deployed to the cluster by a separate Jenkins task.
- The deployment is following a round-robin schedule, where each node is taken off the load balancer to deploy and refresh the software.
- The deployment time is highly predictable and almost constant.
- As soon as a node is returned to the cluster, verification begins.
- Rollback (Disaster recovery) – In case of a bad deployment, despite all the testing and verification, rollback to the last stable deployment. Just like the cut-over deployment above, the time is predictable for a full rollback.

Preparing
for rollback – The roll back process goes through test server.
Implementation: Our tools

- Jenkins – Jenkins is the user interface to the whole process. We used parametrized builds whenever we required a developer to interact with a certain job.
- Jenkins Batch Task plugin – We automated all repetitive tasks to minimize human error. The Task Plugin was used extensively so that we have the flexibility to write scripts to do exactly what we want.
- Bash – Most of the hard work is done by a set of Bash scripts. We configured keyless login from the build server with appropriate permissions, so that these scripts can perform just like a human, once told what to do via Jenkins.
- Ant – The build scripts for the software were written in Ant. Ant also couples nicely with Jenkins and can be easily called from a shell script when needed.
- JUnit and Selenium – Automation is great, but without a good feedback loop, can lead to disaster. JUnit tests provides us with feedback for every single build, while Selenium does the same for ones that are promoted to the test environment. An error means immediate termination of the deployment pipeline for that build. This coupled with testing done by QA keep defects reaching production to a minimum.
- Puppet – Puppet (http://puppetlabs.com) is used by the operations team to manage configurations across environments. Once the operations team build a server for the developers, they have full access to go in and configure it to run the application. The most important part is to record everything we do while in there. Once a developer is satisfied that the configuration is working, they give a walk-through to the operations team, who in-turn update their Puppet Recipes. These changes are rolled out to the cluster by Puppet immediately.
- Monitoring – The logs from all production nodes are harvested to a single location for easy analysis. A health check page is built into the application itself, so that we can check the status of the application running in each node.
Conclusion
Neither DevOps nor Continuous delivery
is a silver bullet. However, nurturing a culture, where developers
and operations trust each other and work together can be very
rewarding to a business. Cultivating such a culture allows a business
to reap the full benefits of an Agile development process. Because of
the mutual trust between us (the developers) and our client's
operations team, we were able to implement a deployment pipeline that
is capable of delivering features and fixes within hours if
necessary, instead of months. During a crucial marketing campaign,
this kind of agility allowed our client to keep the software
infrastructure well in-tune with feedback received through their
marketing analytics and KPIs.
Further reading
A few articles you might find
interesting.