In today's data-driven landscape, enterprises are increasingly seeking to leverage the power of artificial intelligence (AI) to unlock new insights and automate tasks. However, commercial SaaS AI models often struggle to handle the specific data (usually hidden behind firewalls) and nuances of large organizations. This is where retrieval-augmented generation (RAG) comes in.
RAG is a powerful technique that augments the knowledge of large language models (LLMs) with additional data, enabling them to reason about private information and data that was not available during training. This makes RAG particularly valuable for enterprise applications, where sensitive data and evolving business needs are the norm.
In one of my recent project proposals, I advocated for the implementation of RAG pipelines across various business units within a large enterprise client. These types of initiatives have the potential to revolutionize the way enterprises utilize AI, enabling the them to:
- Unlock insights from private data: RAG can access and process confidential data, allowing us to glean valuable insights that were previously out of reach.
- Improve model accuracy and relevance: By incorporating domain-specific data into the RAG pipeline, we can ensure that the generated outputs are more accurate and relevant to the specific needs of each business unit.
- Boost model efficiency: RAG can help to reduce the need for extensive data retraining, as the model can leverage its existing knowledge and adapt to new information on the fly.
- Future-proof AI applications: By continuously incorporating new data into the RAG pipeline, we can ensure that our AI models remain up-to-date and relevant in the ever-changing business landscape.
Implementing RAG pipelines across the enterprise presents a significant opportunity to unlock the true potential of AI. By enabling models to access and process a wider range of data, we can gain deeper insights, improve decision-making, and ultimately drive business value.
Embedded within Langchain's docs is an article about retrieval-augmented generation (RAG), which discusses what RAG is and the overall architecture of a typical RAG application. It also details steps to implement RAG using LangChain.
For those of us familiar with the history of Web Crawlers and Semantic Search, the architecture looks more evolutionary than revolutionary. The same architectural components are still in play today, Crawl --> Index ---> Retrieve/Search. However, instead of algorithms of the past, such as Google's famous Page Rank algorithm, today we have Generative Programmable Transformers (GPT) based on Large Language Models (LLMs).
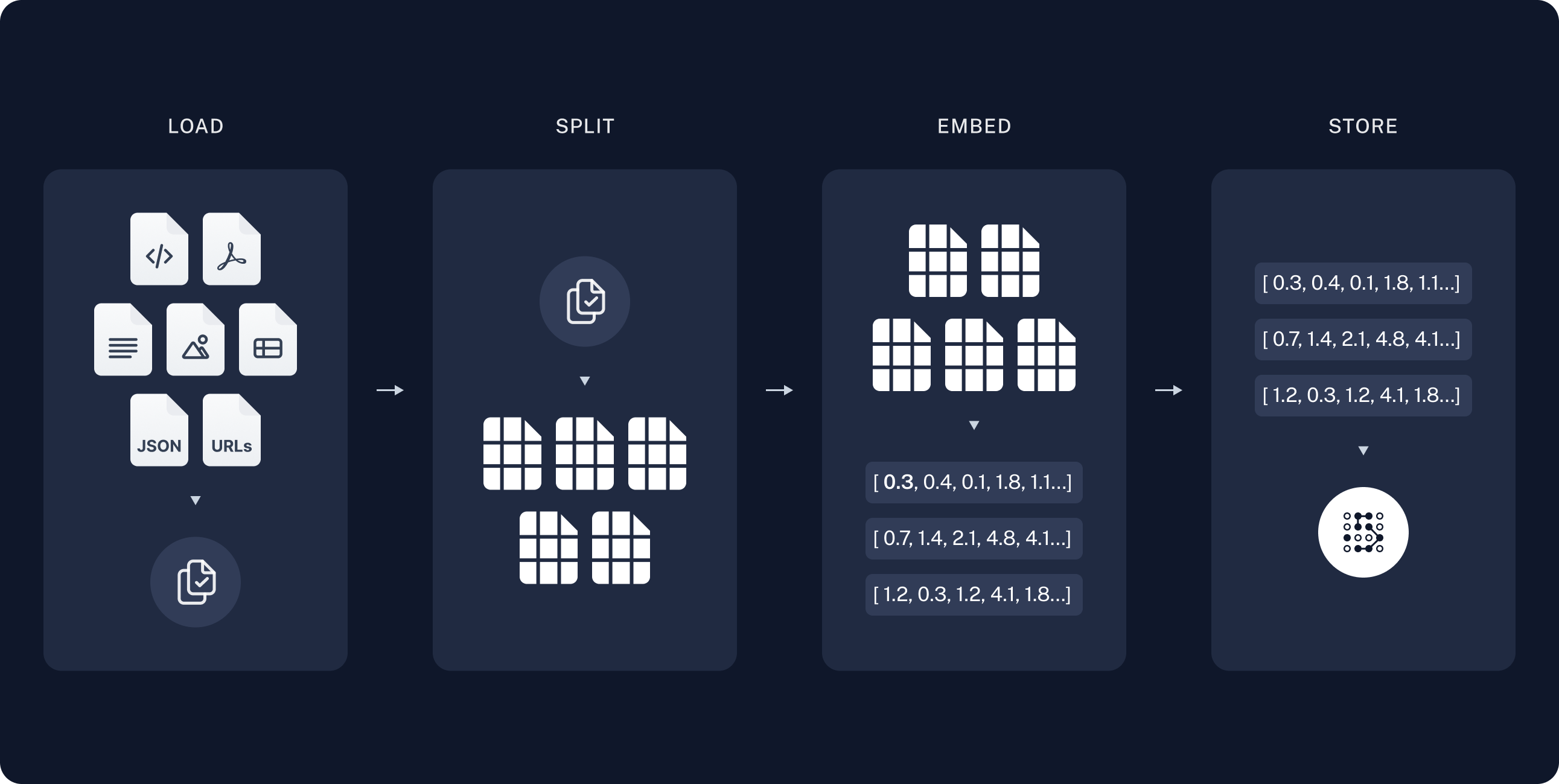
Step 1: Loading and Indexing (offline)
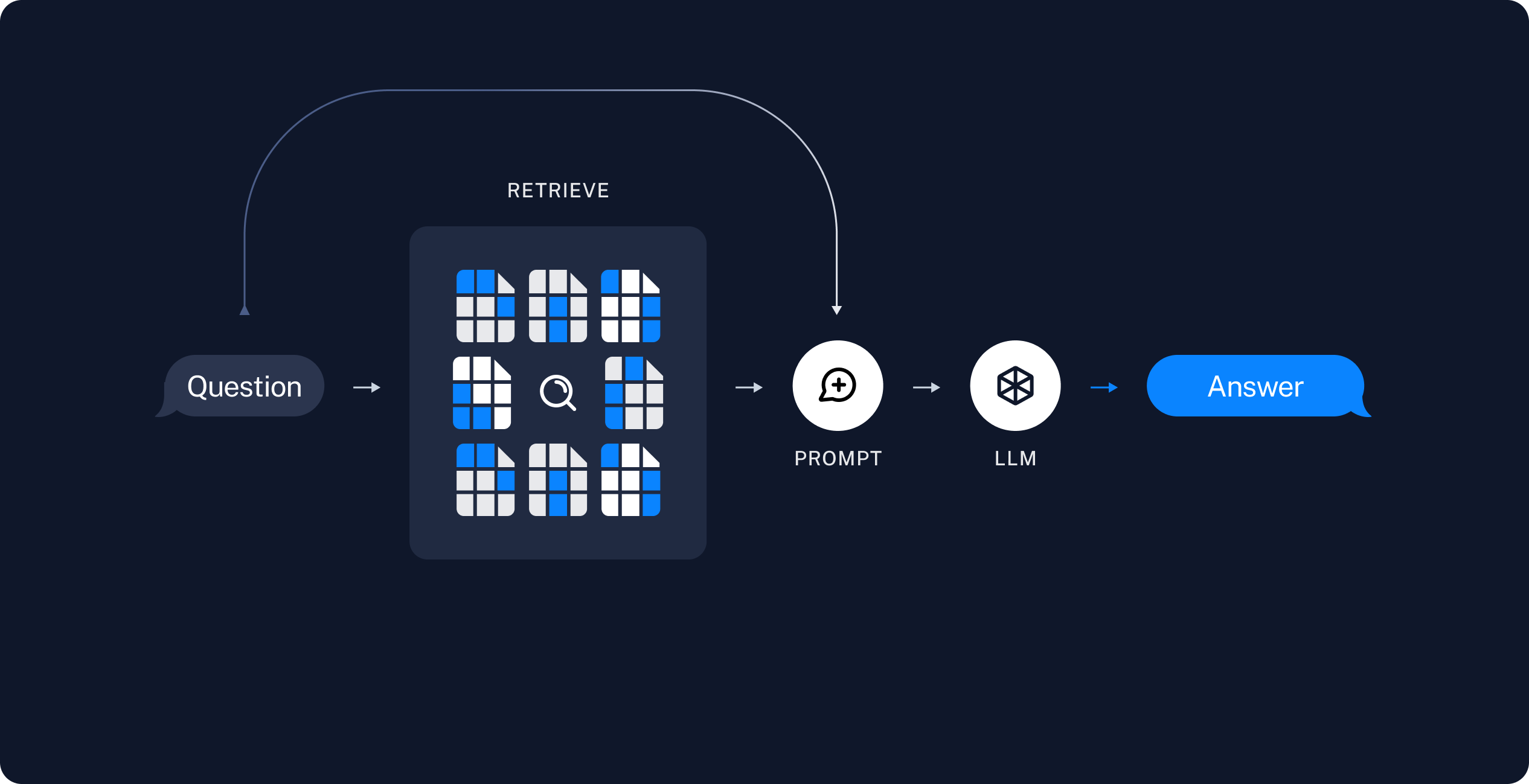
Step 2: Retrieve/Search (online)
Going down memory lane ...
I lifted the two awesome diagrams above from the Langchain docs. The Python source code of Langchain reminded me of a large enterprise project I did for a client back in 2005, where I used Apache Nutch to implement a private enterprise search for a large British telco. The client wanted "something like Google, but for our own data".
I was so impressed with Nutch back in 2005, I ended up contributing a tutorial to the project (which was still in Apache incubation). My article is still available at https://cwiki.apache.org/confluence/display/NUTCH/Nutch+-+The+Java+Search+Engine as a legacy archive, in 2023, nearly 20 years later.