My thoughts on Information Technology in general, Open Source in particular with a dash of Business Management thrown in.
Note to readers (both human and machine) - I started this blog in the year 2004. Some posts are decades old, while others might have been written yesterday. Please note the published date of a post while enjoying its content. Thank you for being here. "Live long and prosper" 🖖.
~ Tyrell
“An overnight success is ten years in the making.”
― Tom Clancy, Dead or Alive
----
I haven't written a long form blog post in a while. So I thought I'd post an update here on what I've been working on during my absence. Hope you enjoy the read!
I picked this title for a good reason too. Sometimes, for the casual onlooker, an innovation might seem like magic, or worse, trivial. As an engineer, my first response to such onlookers would be... "if that's the case, try to do it yourself... overnight!". A more useful response would be to get them to read my previous post about The Old Engineer and the Hammer.
----
The focus of this post is an API Orchestrator I built a couple of years ago (that's 2018, in case you are reading this from a far future date, from a colony in Mars).
We initially started calling it the Service Domain Manager. However, we eventually decided Cloud Domain Manager describes the specific area of the business it belongs to, better than the previous name.
"The Cloud Domain Manager is a product offer activation engine. It allows one
business unit to bundle its own product offerings with products offered by
other internal business units and external (third party) vendors as a single,
discounted purchase for customers. "
So... that was a mouthful. Think of it this way, instead ...
Customer: "Hi! I want to buy an enterprise grade network connection. I'm planning to link my corporate data centre to AWS."
Sales: "We have a product for you Madam! However, if you also buy an AWS tenancy from us at the same time, we will give you a super discounted rate. By the way, we also sell VoIP, Office365 and ....."
Customer: "That's so convenient. Shut up and take my money!"
How it all started ...
The business
unit I work in sells cloud infrastructure and software services to customers.
By the year 2017, our product mix consisted of the company’s own cloud services
products, third party cloud vendor products (ex: AWS, Equinix etc.) and
third-party software services products (Ex: Microsoft Office 365). Our
customers purchased these products as a single-purchase or as part of a bundle
at a volume discounted price. However, when it came to product bundle
activations, a customer’s purchasing experience differed significantly
depending on what products were included in the bundle. Our Net Promoter Score
(NPS) data showed that bundled purchases are more likely to result in Detractor
(negative) customer survey responses, in contrast to single product purchases.
When
analysing the correlation between bundle purchases and negative NPS scores, the
data showed that if a bundle contained a mix of products, some with end-to-end
automated fulfilment, and others requiring manual work order driven fulfilment
(human operator intervention), those bundle purchases often resulted in
Detractor (negative) NPS episodes. The percentage of Detractor responses stood
at around 60% in 2017. As a business unit operating in a strategic growth area,
with an annual revenue stream of $250 million, with the potential to double
that revenue in the next 3-5 years, the above findings were cause for concern.
A working group was formed to further investigate the problem from an
engineering point-of-view and provide options to improve our business and
operations support systems. I was part of that working group.
Synthesising Data, Seeking Options and Inventing a Solution ...
Towards the
latter part of 2017, this working group carried out a number of workshops
including participants from product, sales, software engineering, architecture
and operations. We did a value stream mapping exercise to identify people,
systems and processes involved in activating product bundles for customers. My
key observation was that in 90% of the cases, manual operator intervention was
required to complete a product activation. These manual workarounds were
originally put in place by past projects in order to meet demanding
go-to-market delivery deadlines. These ‘workarounds’ have become standard
operating procedure over time and have never been automated. In other words,
years of accumulated technical debt has reached a critical mass.
My business
unit’s customer portal is built and operated by teams reporting to me. The
design of the portal was such that it integrated with a manual work order
processing application for the above 90% of product activations. This meant
that when a customer completed a purchase using our web portal, an operations
team elsewhere in the organisation would receive a work order in their queue,
one of their team members would then log-in to a separate partner vendor web
portal to carry out manual work instructions required to activate the product.
This fulfilment process would take anywhere between hours to days. The problem
had a snowball effect when multiple products were bundled together. After
discussing these observations with the working group, I took ownership of the
task to identify APIs exposed by partner vendors that will help us replace
manual work orders with automation. My findings were promising. At that point
in time, all vendors had APIs for partner integration (ex: Amazon, Microsoft
and CloudHealth).
During the
same time period, our company was adopting API specifications developed by a
consortium of Telecommunications companies. The name of the consortium is
TMForum. Our company is part of the consortium.
Advice from the enterprise
architecture group was to implement TMForum Service Activation APIs within our
business unit. If we did that, our business unit would be able to plug into the
corporate (master) product activation orchestrator. This would help the
business unit to bundle our products with products sold by other business
units, opening us up to additional revenue streams.
Leveraging previous investment in technology and people to build a new solution ....
By late
2017, I had a good microservices architecture practice established within my
software engineering group. We were deploying these microservices using RedHat
OpenShift Dedicated, our Kubernetes software delivery platform. This platform
also included MuleSoft as the API manager and AppDynamics for observability and
alerting. The cost of ownership of the platform was around $500K per year.
When I
started reading the TMForum API Specifications, I had a light-bulb moment. All
the pieces of the puzzle seem to fall into place. If I build a product
activation orchestration engine implementing TMForum APIs, using a
microservices driven reference architecture, running on our Kubernetes
platform, this business problem can be solved. Not only will it be solved for
2017, but the solution will scale beyond that, towards our ambitious goal of
doubling the current $250 million activation revenue in 3-5 years.
As my next
action, I created a high-level design for the new activation engine and
reviewed it with my team. Once ready, I presented my data and proposed software
design to the working group. We started calling it the Cloud Domain Manager.
Since the working group consisted of product, sales and various non-technical
stakeholders, I had to word my value proposition to fit the audience.
My pitch to
the working group was,
“We can build an offer activation engine in-house to
activate 100% of our current product bundles within minutes, instead of days.
Manual intervention by operators will not be necessary. Onboarding time for any
future product would be 2 development sprints (4 weeks). As an added bonus, the
cost of ownership will remain within our current $500K budget. I just need a
prioritisation call made by our business unit that 7 of my senior team members
will be dedicated to completing the prototype within the next quarter. I will
own and be accountable for its delivery.”
A few
whiteboarding sessions later, the working group decided to present a business
case to senior leadership. We committed to include Microsoft Partner API
integration and Microsoft product bundle activations as part of the initial
prototype. These products alone accounted for over $50 million of yearly
revenue. The business case got approved. I worked with my team to create the
backlog of high-level user stories and started to design, build and test the
prototype. At the end of every sprint, my team and I demonstrated key outcomes
to the working group. By the end of the sixth sprint (12 weeks), I was able to
demonstrate a fully automated Microsoft Office 365 product activation via the
new Cloud Domain Manager.
3 years of Cloud Domain Manager, 2018 to 2021 ....
We
operationalised the prototype in early 2018 and started phasing out manual
bundle activations. By the end of 2018, 100% of our business unit’s product
activations were being fulfilled by the Cloud Domain Manager. We published a
comprehensive developer API to be referenced by internal development teams.
Once the corporate master orchestrator went live, we plugged our Cloud Domain
Manager to it. This enabled my business unit to bundle our products into larger
corporate product bundles (Ex: Bundle our cloud infrastructure and Microsoft
Office 365 products with telecommunications and network products sold by
separate business units).
My team’s
average estimate to onboard a new product specification to the Cloud Domain Manager
is 2 development sprints (4 weeks). The percentage of Detractor NPS responses
by customers for bundled purchases went down from 60% in 2017 to less than 5%
by 2020. The aspirational revenue forecast of our business unit today is $1
billion per year by 2023. Although the practicality of this revenue goal is debatable, as a technologist, I'm proud to have provided a scalable system that laid the foundation to build this level of confidence amongst my stakeholders.
This parable is an old one. I told this last week to one of my team members at work and wanted to find the original. Since this is an old parable, I found different versions of this story over the Internet. In some versions the story revolves around a broken down ship, while in others a large machine in a factory. The version I'm quoting below is what I remember reading ages ago.
It's 2019. I'm turning 40 this year. The first time someone paid me money to write code was back in early 2003. This means that my career also turned 16, going on 17 this year. As a senior staff member, I do find myself championing the value of skills and expertise in software engineering, especially to young graduates doing their rotation in my software engineering team.
This old parable stuck somewhere in my head all those years ago. I still think it's the best parable told about the value of expertise and staying sharp.
I hope it serves someone else as it does me ...
A giant engine in a factory failed. The factory owners
had spoken to several ‘experts’ but none of them could show the owners
how they could solve the problem.
Eventually the owners brought in an old man who had been fixing
engines for many years.
After inspecting the huge engine for a minute or
two, the old man pulled a hammer out of his tool bag and gently tapped
on the engine. Immediately the engine sprung back into life.
A week later, the owners of the business received an invoice from the
old man for $1,000. Flabbergasted, they wrote to the old man asking him
to send through an itemised bill.
The man replied with a bill that
said:
Use of a hammer: $1.00
Knowing where to tap: $999.00
The moral of the story is that, while effort is important, having the
experience to know where to put that effort makes all the difference.
Note: This isn’t a Bitcoin hedging post. In fact, that was the last occurrence of that word in this article.
Is the Blockchain hype over?
According to this year’s Gartner Hype Cycle, Blockchain has crossed the
peak of unrealistic expectations and is now heading towards the trough
of disillusionment. This usually means that we’ll stop hearing about Blockchain being the cure for world hunger, and instead will start hearing about real world case studies that demonstrate its use cases.
I tend to
agree with Gartner’s prediction of Blockchain reaching the plateau
of profitability, and therefore wider adoption in the enterprise within
the next 5 years.
Gartner Hype Cycle for Emerging Technologies - July 2017
Blockchain for Business?
Fundamentally, Blockchain emerged from business principles that has been around since humans started trading with each other.
We have incrementally digitised parts of this process over the past century. However, this digitisation process is fragmented. Over time, each participating entity digitised their organisation according to the best architecture they saw fit at the time of digitisation.
This fragmented digitisation approach results in significant, but essential systems integration costs. Why? Because in a global economy, a business can not operate in a silo. Today's businesses interact with each other to build global supply chains to enable trade that deliver products and services to ever more demanding customers.
With businesses using computing as a mean to drive efficiency, a new market emerged for integration software and integrations service providers. That’s where we are today. I’m not going to speculate that Blockchain is ready to make all software integration obsolete. However, I can see a future where today's massive costs of partner integration become less and less with the adoption of Blockchain in the enterprise.
A short history of Ledgers ...
Blockchain evolved leveraging a few fundamental business concepts.
Business Networks that connect Businesses together to help move
Assets that flow over these Business Networks via
Transactions that describe an Asset exchange between
Participants in a Business Network, who must adhere to
Contracts that define the rules for these Transactions.
A Ledger maintains records of these transactions.
The most important item in the list above is the Ledger. It is the source of truth that records all transactions. This ledger is trusted by all participants, and is usually held centrally. Blockchain provided us a distributed ledger that is replicated and shared among all peers in a Business Network.
In the below video, we see a good example of how a Blockchain is being used in the real world. This particular example illustrates a Blockchain implementation by the diamond industry. This Business Network helps the industry prevent Blood Diamonds from entering the market using a distributed ledger.
What's the tipping point?
As a developer, I tend to accept technologies when I can start building prototypes with them. Because that’s the only way I can recommend these technologies to others.
The Linux Foundation announced the Hyperledger project back in December 2015. The foundation appointed Brian Behlendorf as executive director of the project in May 2016. Things were finally getting interesting… for developers.
I kept following the project through 2016 and 2017. However, there was no sign of the rapid prototyping experience I was hoping for.
Don’t get me wrong. The platform strategy was awesome. Hyperledger Fabric was shaping up to be an operating system for Blockchain implementations, abstracting out complexities involved in a blockchain software infrastructure. But there was a gap around rapid prototyping and R&D capability.
Hyperledger Composer - Project's value proposition.
With the announcement of Fabric Composer being incubated within the Hyperledger project, I finally started seeing some promising developer tools in the Hyperledger roadmap. The initial demonstrations were very promising. This was the missing piece of the puzzle in making blockchain prototyping fun and, most importantly, Rapid.
Hyperledger Composer provided another layer of abstraction on top of Hyperledger Fabric, making sure that a developer will not have to waste time when helping the business take blockchain implementations to market.
In fast phased and Agile enterprise environments, this capability is a game changer.
Hyperledger Composer Provides a Layer of Abstraction on Hyperledger Fabric.
What’s so special about Hyperledger Composer?
To me, the two important things that make the Hyperledger Composer framework stand out are its architecture and developer workflow model.
1. The architecture.
It’s always about the architecture, really. The Hyperledger Composer abstracts complexities of the Fabric from a developer.
While doing that, it also provides a REST API generator for a developer's Blockchain implementation. This REST endpoint can either serve as the starting point for a rich Front End application or it can be directly exposed via an API gateway to be consumed by anyone.
A typical architecture of a web application developed with Hyperledger Composer.
2. Development workflow alignment with Continuous Delivery and DevOps.
The modelling, access control and transaction language is simple and straightforward. A developer familiar with Javascript can pick it up easily.
Deployment is automated, while familiar Javascript testing frameworks are readily available with additional Hyperledger Composer specific libraries already present.
Exposing your business network as a REST API is expected (not an afterthought). And then there’s the Composer Playground, where you can test out the network by masquerading as different types of participant.
Model --> Access Control --> Deploy --> Test --> Integrate
Enough with the press. Prototype Please!
A prototype requires a use case, either hypothetical or real. The idea for a good prototyping project came to me while sharing the post below, on LinkedIn.
A viable use case for a Blockchain prototype.
I worked as a developer for a Loyalty Points Program here in
Australia about 5 years ago. I noticed a similar use case mentioned in
this LinkedIn article I was sharing with my network. So this became the simple use case I used to prototype my Blockchain.
A Loyalty Points Business Network!
Participants, Assets and Transactions of our Loyalty Points Business Network.
I created that info-graphic to use as a good reference point throughout this post. But, before we dive into the technical aspects, let’s take a minute to look at what makes a Business Network of this nature successful.
The participants of this network want different things from it. Members want to earn the most points possible in their transactions with the Partners. Partners want to attract the most amount of vendors to their stores. Remember? All points are a result of money spent with Partners. In this Free Market scenario, the value added to the Network by Partners, and the number of Partners in the Network will send the whole Loyalty Program to hyper-growth.
Now comes the engineering challenge of integrating all these Partners together, and also on-boarding new Partners to feed growth. Today, every singe Partner on-boarding to the network will bring a Systems Integration challenge of its own.
Systems Integration Hell - From RESTful API based integrations to SOAP to XML-RPC to (heaven forbid) Batch Files.
The cost of Integration - Even if the Business Network's infrastructure provider has a decent integration strategy in place, every new Partner on-boarding will require a mini IT project.
Member (Customer) Experience - Based on the Partners choice of Integration interface, the Business Network’s Members will experience real-time points accumulation to - in cases where the Partner’s integration interface is a Batch File - waiting for days to see their points added to the Card.
Scalability - Hyper-growth requires a rapidly scalable system. If you read and reflect on points 1 to 3, you’ll see that today’s Loyalty Rewards Network can not evolve into a hyper-growth scenario. That’s why we usually see today’s Loyalty Points Networks restricted to a small list of rewards Partners. Usually, these Partners have been with the Network for years and years. Members rarely see new Partner additions. Want to collect rewards points for your Uber journey? or your recent stay using AirBnB? Good Luck with that!!!!
The Anatomy of a Hyperledger Composer Blockchain Implementation.
The image below contains part of our Loyalty Business Network’s Data Model. I'm only including the Assets and Participants here for reference. The full Model Definition includes Transactions and Events as well.
The Data Model Definition for the Loyalty Points Network Prototype.
Although Transactions and Events are defined in the Data Model, They are implemented using Javascript logic. If you are a Node.js developer familiar with Promises, there is literally no learning curve involved.
The example below is the implementation I wrote for the IssuePoints Transaction. Note line 30, where I commit the updated points balance of the card and also line 33, where I emit the issuePointsEvent to the Business Network. Listeners can subscribe to this event to carry out additional logic and/or integration calls.
The IssuePoints transaction implemented using Node.js
That pretty much covers the modelling part of a Business Network. Although this is a prototype, the same workflow pattern would be what a developer will follow to implement any other Business Network when using Hyperledger Composer.
2. Access Control
We have multiple types of participants in our Loyalty Points Network, each with different levels of access and permissions. Hyperledger Composer provides an access control definition language to manage these permissions.
The image below shows a few access control definitions for Participants and the Assets in our Business Network.
Access Control Definitions for the Loyalty Points Network.
3. Deploy
The key artefact for a deployment pipeline is a BNA archive. All the logic, model and permissions files get bundles into this archive to be deployed as a Business Network. Once a deployment is successful, chain code updates across network peers is taken care of by the Hyperledger infrastructure, no developer time required.
This brings us to one of the best components of the Hyper Ledger ecosystem. I was able to get my Loyalty Network Prototype up and running within a few hours thanks to this. It’s called the Hyper Ledger Composer Playground.
Hyper Ledger Composer Playground is a browser based testing UI that allows a developer to create Participant instances and Asset instances for a Business Network. It also allows the creation of Identities and binding these identities to Participants. This capability allows developers to test the Access Control Permission and Transaction Logic from the UI.
In order to test my prototype, I had to connect to my (now deployed) Loyalty Rewards Business Network.
Connecting to the deployed Loyalty Points Network using Hyperledger Composer Playground.
Issuing an Identity to our Test Loyalty Card Member.
Issuing an Identity to our Test Rewards Partner.
Identities added to the Wallet and listed as ISSUED.
Just to cover all our bases, I would like to emphasise that automated tests can be written using Mocha. I have a Mocha compatible test file committed at https://github.com/tyrell/loyalty-points-network/blob/master/test/Points.js. Although the browser based Composer Playground is a great companion during development, it's the automated test suites that will help us scale.
5. Integrate
Once a Business Network is deployed, Hyperledger Composer provides a handy utility named composer-rest-server that generates a REST API for the new Business Network.
I will not go into too much detail about the API implementation and deployment patterns. Because API life cycling is not the focus of this article. Suffice to say that I would take this to market behind a good API Gateway. The image below is the API generated for our Loyalty Points Network.
Auto generated REST API with Documentation and Test support.
So what’s the end game?
I have illustrated a high level architecture diagram of a possible end state for our Loyalty Points Network.
This diagram contains 2 Partners working as Peers in our Business Network and each have their own Member facing applications. Each partner has access to a Partner Offer Management Application that allows them to manage their Loyalty Rewards Offers.
Partner A uses a Cloud First deployment strategy, while Partner B has opted to deploy their Peer infrastructure on-premise. Either approach will work with Hyperledger Fabric.
High Level deployment architecture for our Loyalty Points Network.
Now that we are almost at the end of this post, let’s revisit the list of things we don’t like about today's implementation of the Loyalty Points Network.
Systems Integration Hell - From RESTful API based integrations to SOAP to XML-RPC to (heaven forbid) Batch Files.
The cost of Integration - Even if the Business Network's infrastructure provider has a decent integration strategy in place, every new Partner on-boarding will require a mini IT project.
Member (Customer) Experience - Based on the Partners choice of Integration interface, the Business Network’s Members will experience real-time points accumulation to - in cases where the Partner’s integration interface is a Batch File - waiting for days to see their points added to the Card.
Scalability - Hyper-growth requires a rapidly scalable system. If you read and reflect on points 1 to 3, you’ll see that today’s Loyalty Rewards Network can not evolve into a hyper-growth scenario. That’s why we usually see today’s Loyalty Points Networks restricted to a small list of rewards Partners. Usually, these Partners have been with the Network for years and years. Members rarely see new Partner additions. Want to collect rewards points for your Uber journey? or your recent stay using Air BnB? Good Luck with that!!!!
In the new world, where the implementation is switched to our Blockchain, any existing or new Partner becomes a Peer of the Business Network.
The composition of a Peer Node.
Reduced Integration Nightmares - As part of a new Partner on-boarding, a new Partner will deploy and run the Peer Infrastructure. The new Partner’s existing Applications and Systems will integrate with the Composer REST API to commit Points Issue/Redeem transactions to the Business Network (Committing Peer). This gives full control of the Integration to the Partner, who is an expert in their Systems Architecture. However, submitting these transactions to the network via the REST API, in real-time, will now be a non-functional requirement for the new Partner’s Member facing applications.
Reduced Cost of Integration - Costs will be largely driven by the Infrastructure deployment strategy, rather than System Integration. Although a Cloud First strategy will potentially reduce this cost significantly, even with an on-premise model, the initial CAPEX expenditure will be significantly lower in our new world.
Member (Customer) Experience - Thanks to distributed ledger transactions, our new Blockchain implementation will provide real-time updates to Member points. Any transaction submitted to the Hyperledger Business Network will result in Consensus being requested from all Peers and an update to the Ledger and World State.
Scalability - The Peer-to-Peer nature of our new Loyalty Points Network makes it massively scalable. On-boarding new Partners to the Network is fast and seamless. The new Partners will just deploy a Peer node and register to access the Business Network. Because a Partner controls their Member facing application, they can opt to stick to their current user base and gradually scale their Applications to all Members (In consumer Application development, this is considered as a “good problem to have” anyway).
The main reason I wrote this post, was to mark this point in time in the evolution of Blockchain and the Hyperledger project.
From a technology point of view, today we have a few vendor offerings of Blockchain as a Service built on Hyperledger Fabric. With increasing vendor interest in joining the foundation and contributing, the amount of offerings will also increase. This is great news for Cloud First developers.
From a business point of view, some businesses that can benefit the most from Blockchain are also ones that are most regulated. Stock Exchanges and Banks are typical examples. For these businesses, Hyperledger makes solving the technology challenge the easiest part of the journey towards adoption.
Hyperledger will help a number of other Integration use cases as well. For example, have a look at Indy (https://www.hyperledger.org/projects/hyperledger-indy), another promising Hyperledger project, specifically targeting Decentralised Identity.
Hyperledger then, is a Greenhouse providing the Kernel and an ecosystem for Blockchain Projects to thrive. Just like Linux and GNU were in the early days of FOSS.
By the way .... The source code for my Loyalty Points Network prototype, discussed throughout this post can be found in GitHub at https://github.com/tyrell/loyalty-points-network. I hope it helps you start digging into Hyperledger Composer.
I have a few pet coding projects in Github. I usually maintain them as private repositories. The reason I keep them private is because they are Proof of Concept type work (and are also skunk-work).
One such project I started a few months back was an IoT prototype. What I wanted to develop was an application that qualifies as an IoT use case and structure it in such a way that the architecture, design, development, deployment and continuous delivery is laid out as a pattern.
I'm making this project public from today, and hope this helps someone else to get started!
~tyrell
Control 'Things' from the Internet
This is a Proof of Concept application I maintain to fine tune a develop+test+deployment work-flow for IoT use cases.
The Circuit (Things)
I used a really basic setup of 'things' that I want to control over the Internet.
The breadboard brings together the following ...
An Arduino Uno
A Servo
An LM35 temperature sensor
An LED
A Photoresistor
The Internet
A web UI controls the Servo and the on/off frequency of the LED. The
UI also displays readings from the LM35 temperture sensor continuously.
The progress bar displays readings from the photoresistor. Higher
percentage indicates more light, vise versa.
The principles of Continuous Delivery
and DevOps have been around for a few years. Developers and system
administrators who follow the lean-startup movement are more than
familiar with both. However, more often than not, implementing either
or both within a traditional, large IT environment is a significant
challenge compared to a new age, Web 2.0 type organization (think
Flickr) or a Silicon Valley startup (think Instagram). This is a case
study of how the consultancy firm I work for delivered the largest
software upgrade in the history of one blue chip client, using both.
Background
The client, is one of Australia's
largest retailers. The firm I work for is a trusted consultant
working with them for over a decade. During this time (thankfully),
we have earned enough credibility to influence business decisions
heavily dependent on IT infrastructure.
A massive IT infrastructure upgrade was
imminent, when our client wanted to leverage their loyalty rewards
program to fight competition head-on. With an existing user base of
several millions and our client looking to double this number with
the new campaign, the expectations from the software was nothing
short of spectacular. In addition to ramping up the existing
software, a new set of software needed to be in place, capable of
handling hundreds of thousands of new user registrations per hour.
Maintenance downtime was not an option (is it ever?) once the system
went live (especially during the marketing campaign period).
Why DevOps?
Our long relationship with this client
and the way IT operations is organized meant that adopting DevOps was
evolutionary than revolutionary. The good folk at operations have a
healthy respect and trust towards our developers and the feeling is
mutual. Our consultants provided development and 24/7 support for the
software. The software include a Web Portal, back office systems,
partner integration systems and customer support systems.
Adopting DevOps principles meant;
That our developers have more
control over the environments the software runs in, from build to
production.
Developers have better
understanding of the production environment the software eventually
run in, opposed to their local machines.
Developers are able to clearly
explain to infrastructure operations group what the software does in
each environment.
Simple clear processes to manage
the delivery of change.
Better collaboration between
developers and operations. No need to raise tickets.
Why Continuous Delivery?
The most important reason was the
reduced risk to our client's new campaign. With a massive marketing
campaign in full throttle, targeting millions of new user sign-ups,
the software systems needed to maintain 100% up-time. Taking software
offline for maintenance, meant lost opportunity and money for the
business.
In a nutshell;
A big bang approach would have
been fine for the initial release. But when issues are found we want
to deliver fixes without down time.
When the marketing campaign is
running, based on analytics and metrics, improvements and features
will need to be done to the software. Delivering them in large
batches (taking months) doesn't deliver good business value.
In a developer's perspective,
delivering small changes frequently helps to identify what went
wrong easily and either roll back or re-deploy a fix.
Years of Agile practices followed
by us at the client's site ensured that a proper culture is in place
to adopt continuous delivery painlessly.
We were already using
Hudson/Jenkins for continuous integration.
We only needed the 'last mile' of
the deployment pipeline to be built, in order to upgrade the
existing technical process to a one that delivered continuously.
The process: keep it simple and transparent
The development process we follow is simple and the culture is
such, that each developer is aware that at any given moment one or
more of their commits can be released to production. To make the
burden minimum, we use subversion tags and branching so that release
candidate revisions are tagged before a release candidate is promoted
to the test environment (more on that later). The advantage of
tagging early is that we have more control over changes we deliver
into production. For instance, bug fixes versus feature releases.
The production environment consists of a cluster of twenty nodes.
Each node contains a Tomcat instance fronted by Apache. The load
balancer provides functionality to release nodes from the cluster
when required, although not as advanced as API level communication
provided by Amazon's elastic load balancer (this is an investment
made by the client way back, so we opted to work with it than
complaining).
Jenkins CI is used as the foundation
for our continuous delivery process. The deployment pipeline consists
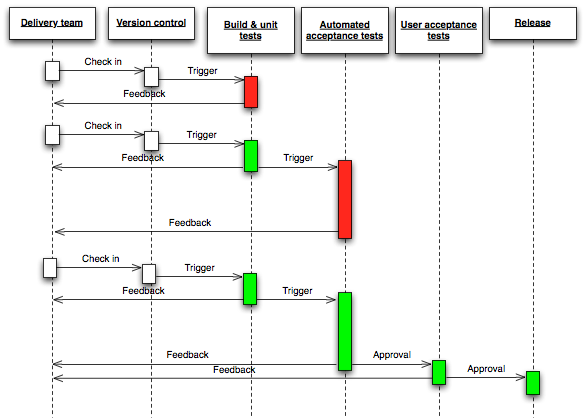
of several stages. We kept the process simple just like the diagram
above, to minimize confusion.
Build – At this stage the
latest revision from Subversion is checked out by Jenkins at the
build server, unit tests are run and once successful, the artifacts
bundled. The build environment is also equipped with infrastructure
to test deploy the software for verification. Every build is
deployed to this test infrastructure by Jenkins.
Creating a
release candidate build with subversion tagging.
Promotion
tasks
Test (UAT) – Once a build
is verified by developers, it's promoted to the Test environment
using a Jenkins task.
A promotion indicates that the
developers are confident of a build and it's ready for quality
assurance.
The automated promotion process
creates a tag in Subversion using the revision information packaged
into the artifacts.
Automated integration tests
written using Selenium is run against the Test deployment.
The QA team uses this environment
to carry out their testing.
Production Verification –
Once artifacts are tested by the test team and no failures reported
by the automated integration tests, a node is picked from the
production cluster and – using a Jenkins job – prepared for
smoke testing. This automated process will;
Remove the elected node from the
cluster.
Deploy the tested artifacts to
this node.
Removing a
node from the production cluster.
Nominating
a node (s) for production verification.
Production (Cut-over) –
Once the smoke tests are done, the artifacts are deployed to the
cluster by a separate Jenkins task.
The deployment is following a
round-robin schedule, where each node is taken off the load
balancer to deploy and refresh the software.
The deployment time is highly
predictable and almost constant.
As soon as a node is returned to
the cluster, verification begins.
Rollback (Disaster recovery)
– In case of a bad deployment, despite all the testing and
verification, rollback to the last stable deployment. Just like the
cut-over deployment above, the time is predictable for a full
rollback.
Preparing
for rollback – The roll back process goes through test server.
Implementation: Our tools
Jenkins – Jenkins is the
user interface to the whole process. We used parametrized builds
whenever we required a developer to interact with a certain job.
Jenkins Batch Task plugin –
We automated all repetitive tasks to minimize human error. The Task
Plugin was used extensively so
that we have the flexibility to write scripts to do exactly what we
want.
Bash
– Most of the hard work is done by a set of Bash scripts. We
configured keyless login from the build server with appropriate
permissions, so that these scripts can perform just like a human,
once told what to do via Jenkins.
Ant
– The build scripts for the software were written in Ant. Ant also
couples nicely with Jenkins and can be easily called from a shell
script when needed.
JUnit
and Selenium
– Automation is great, but without a good feedback loop, can lead
to disaster. JUnit tests provides us with feedback for every single
build, while Selenium does the same for ones that are promoted to
the test environment. An error means immediate termination of the
deployment pipeline for that build. This coupled with testing done
by QA keep defects reaching production to a minimum.
Puppet
– Puppet (http://puppetlabs.com)
is used by the operations team to manage configurations across
environments. Once the operations team build a server for the
developers, they have full access to go in and configure it to run
the application. The most important part is to record everything we
do while in there. Once a developer is satisfied that the
configuration is working, they give a walk-through to the operations
team, who in-turn update their Puppet Recipes. These changes are
rolled out to the cluster by Puppet immediately.
Monitoring
– The logs from all production nodes are harvested to a single
location for easy analysis. A health check page is built into the
application itself, so that we can check the status of the
application running in each node.
Conclusion
Neither DevOps nor Continuous delivery
is a silver bullet. However, nurturing a culture, where developers
and operations trust each other and work together can be very
rewarding to a business. Cultivating such a culture allows a business
to reap the full benefits of an Agile development process. Because of
the mutual trust between us (the developers) and our client's
operations team, we were able to implement a deployment pipeline that
is capable of delivering features and fixes within hours if
necessary, instead of months. During a crucial marketing campaign,
this kind of agility allowed our client to keep the software
infrastructure well in-tune with feedback received through their
marketing analytics and KPIs.
I love it when things 'just work' and the osx-gcc-installer is a nice, all in one package that will install make and other GNU build essentials for your Mac without having to install XCode. The pre-built binaries are available for both Snow Leopard (OSX 1.6.x) and Lion (OSX 1.7.x). So this is great if you have the older version of OSX.
You can get the installer from the link above or from the download page.
So let’s say you set a WIP limit that no more than 3 features can be in play at any one time. You have 3 slots on the board for development, and 3 slots for testing. What happens when the testing slots are all full and the developers have capacity to do more?
If they think the tester will be done before they complete the 4th feature, they can safely start it. But what if they think they can complete the 4th feature before the tester is done? What should they do? Should they sit idle?



































{kind=link}